PDFからテキストを抽出:究極のプライバシー重視コンバーター
高度な「PDFからテキストを抽出」ツールを使用して、ドキュメント内に閉じ込められたデータを解放しましょう。研究者、学生、データアナリストのいずれであっても、静的なPDFファイルから編集可能なテキストを抽出することは頻繁に必要となります。当社のツールを使用すると、高価なソフトウェアやインターネット依存のクラウドサービスを必要とせずに、PDFコンテンツをプレーンテキスト(TXT)形式に即座に変換できます。
機密文書を扱う最も安全な方法を体験してください。他のコンバーターとは異なり、当社はセキュリティを最優先しています。ファイルがデバイスから離れることはありません。すべての処理はブラウザ内でローカルに行われ、データのプライバシーを100%保証します。ログインも登録も不要で、サーバーへのアップロードは一切ありません。
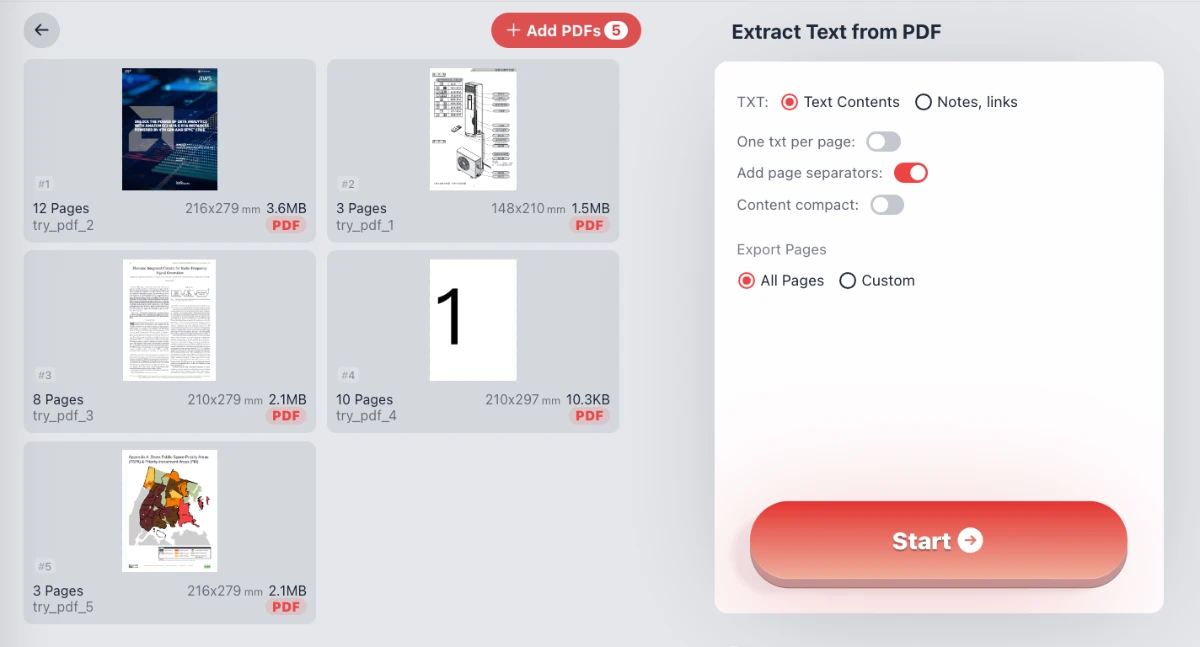
主な機能と特徴
当社のツールは、柔軟性と一括処理のために設計されています。直感的なインターフェースに基づいて、データの抽出方法を完全に制御できます。
- 一括処理: 複数のPDFを一度にアップロードできます。プレビューに表示されているように、ファイル(例:try_pdf_1からtry_pdf_5)をキューに入れ、同時に処理して時間を節約できます。
- デュアル抽出モード:
- テキストコンテンツ: 編集や閲覧のためにドキュメントから本文テキストを抽出します。
- メモとリンク: ハイパーリンクと注釈データを特別に収集し、参照を集める研究者に最適です。
- カスタムフォーマットオプション:
- ページ区切りを追加: 出力テキストファイルのページ間にきれいな区切りを挿入し、ドキュメントの構造を維持します。
- 1ページにつき1つのTXT: 各PDFページを個別のテキストファイルに分割するか、結合したままにするかを選択します。
- コンパクトコンテンツ: 余分な空白を削除し、データ分析に適した密度の高い出力にします。
- 正確なページ選択: ドキュメント全体を抽出する必要はありません。「カスタム」範囲機能を使用して、正確なページ(例:「5, 6-10」)を指定するか、単に「すべてのページ」を選択します。
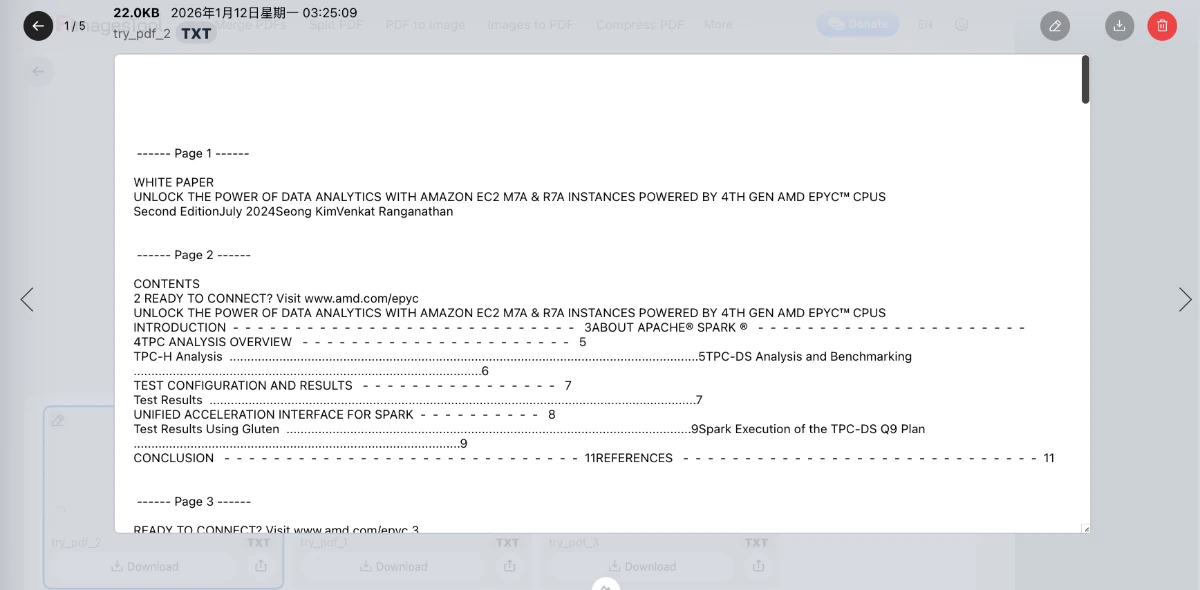
なぜブラウザベースの処理を選ぶのか?
デジタル時代において、データのプライバシーは最も重要です。従来のオンラインコンバーターでは、ファイルをリモートサーバーにアップロードする必要があり、機密契約、法的書類、または個人データに脆弱なポイントが生じます。
当社のソリューションは異なります:
- アップロードゼロ: 実際のファイルデータがネットワーク上を移動することはありません。
- 瞬時のスピード: アップロードやダウンロードの待ち時間がないため、抽出はコンピュータの処理速度と同じ速さで行われます。
- オフライン対応: ページが読み込まれれば、インターネット接続がなくてもテキストを抽出できます。
よくある質問 (Q&A)
このPDFからテキストへのツールは無料ですか?
はい、このツールは完全に無料です。隠されたペイウォール、サブスクリプション料金、または処理できるファイル数の制限はありません。
登録やソフトウェアのインストールは必要ですか?
いいえ。これは純粋にWebベースのツールです。アカウントを作成したり、ログインしたり、実行可能なソフトウェアをダウンロードしたりする必要はありません。最新のWebブラウザ(Chrome、Firefox、Edge、Safari)ですべて動作します。
ドキュメントのデータは安全ですか?
もちろんです。高度なブラウザ技術(WASM)を使用して、PDFファイルをデバイス上でローカルに処理します。ドキュメントが当社のサーバーに送信されることは決してないため、100%のプライバシーとセキュリティが保証されます。
特定のページのみを抽出できますか?
はい。右側の設定パネルで、「ページのエクスポート」オプションを「カスタム」に切り替えます。その後、特定のページ番号または範囲(例:1-3, 8)を入力して、それらのセクションからのみテキストを抽出できます。